This study provides the first evidence of an association between the MC4R rs79783591 variant and cancer, suggesting a potential role as a risk and prognostic factor in TGCT. Carriers showed an increased mortality risk, adjusted for BMI, disease location, and histology, and were diagnosed at a median age four years earlier than non-carriers. These findings are consistent with observations in Hispanic populations, who often present with more aggressive and chemoresistant disease at younger ages; these patterns do not appear to be fully explained by sociodemographic factors (6, 7, 19, 20). Although statistical significance was limited by sample size, simulated cases confirmed a threefold increase in mortality.
The variant (rs79783591, c.806T > A; p.Ile269Asn) lies in MC4R (18q21.32), with a gnomAD frequency of 0.00011 and 0.00629 in the Mexican PAGE cohort. Despite its conflicting ClinVar classification (18), the variant has been associated with obesity in Mexican children and adults (9); however, carriers here exhibited relatively normal BMI values. TGCT has high heritability, but no high-penetrance germline variants or validated prognostic genetic markers have been established (21–23). Functional hypotheses suggest that MC4R variants may influence germ cell survival via anti-apoptotic pathways, potentially disrupting the balance between proliferation and apoptosis (11). Confirmation of these associations and clarification of underlying mechanisms will require larger, multi-center studies. Additionally, we were unable to calculate the haplotype as the presence of another potentially associated variant could not be excluded.
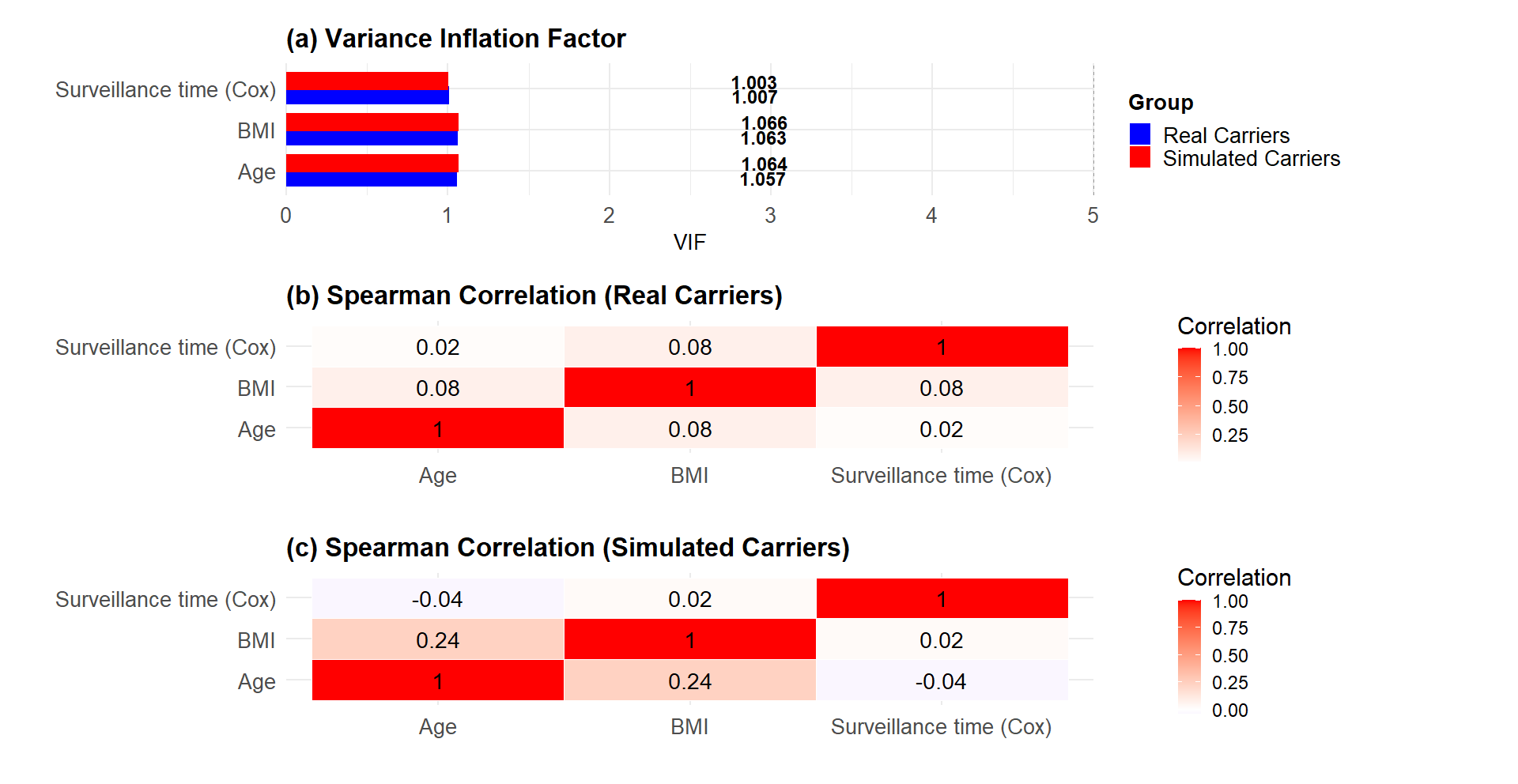
To address the limitations of small sample size, we implemented synthetic data generated with synthpop, which improved model performance, narrowed confidence intervals, and enabled detection of significant Kaplan–Meier differences that were only marginal in the real dataset, while preserving significance in multivariate analyses. This approach preserves the trends of the original cohort while enhancing statistical power and has been shown to outperform other methods, such as deep learning-based Generative Adversarial Networks (GANs), particularly in small, tabular clinical datasets (14, 15, 24–26). In fact, given the extremely limited number of carriers in our study (n = 9), the use of GANs would be impractical due to overfitting and instability in training, further supporting the choice of CART-based synthetic data generation as a more robust and transparent alternative. While synthetic data provide valuable insights and help identify potential prognostic factors, they do not perfectly reflect real populations and may introduce bias if original data variability is limited.
Complementary tests sensitive to early- and late-event differences (Peto-Peto and Tarone-Ware) confirmed trends in the real cohort and detected significant differences in the synthetic cohort, supporting the utility of synthetic data to increase statistical power.
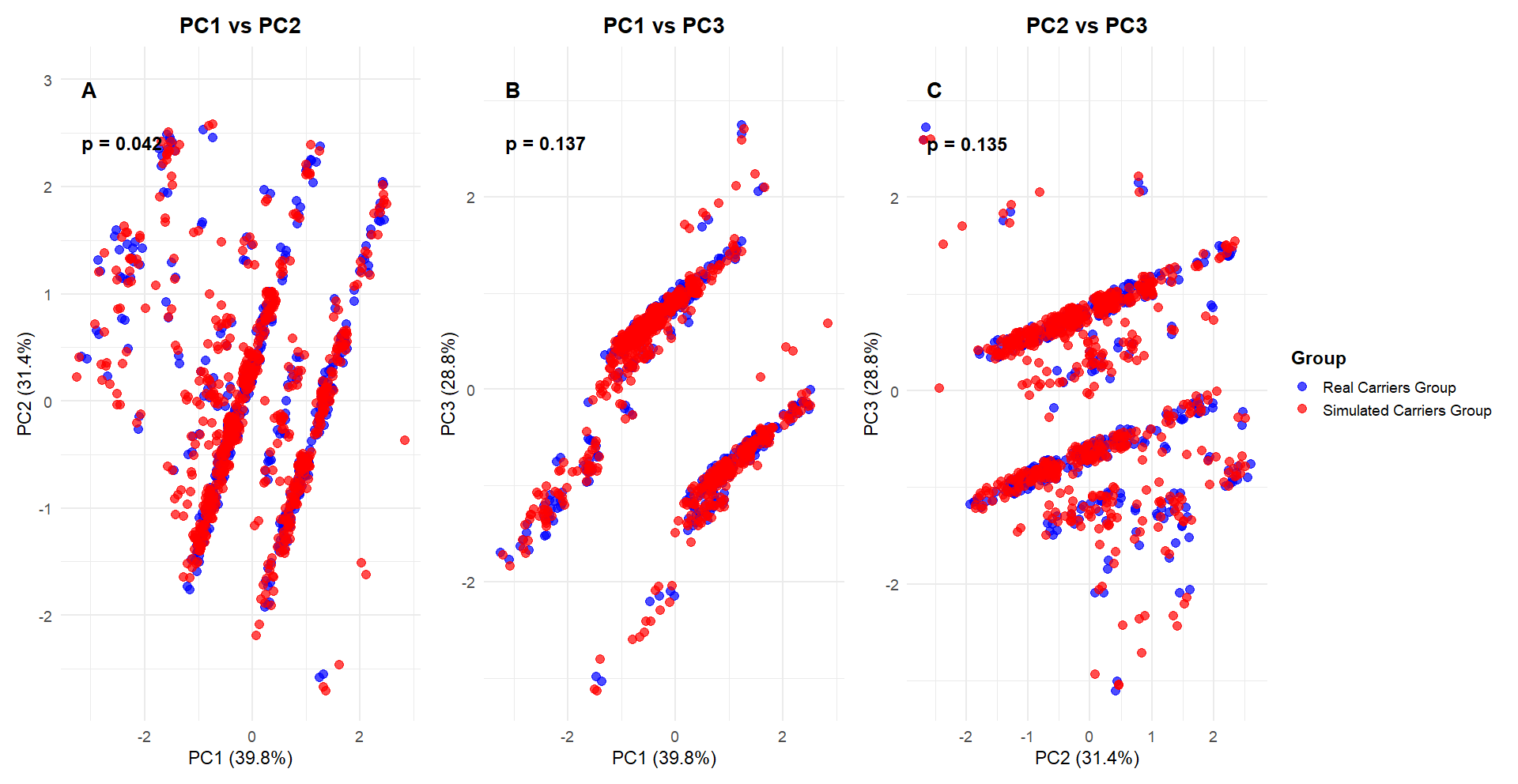
While synthetic data provide valuable insights, limited variability in the original cohort may introduce bias, potentially distorting observed clinical patterns. As shown in our Kaplan–Meier analysis, a “fall” was observed due to such variability, which might not reflect true clinical behavior. Permutation analyses of PCA components further highlighted that some relationships between variables may be incompletely captured. These limitations emphasize that even within small cohorts, increasing the number of cases and its diversity can improve robustness and reduce potential distortions. Importantly, the synthetic cohort produced lower standard errors and slightly reduced C-index values compared to the real cohort, indicating more precise and stable estimates of the variant’s effect while preserving discriminative ability.
Despite the small cohort size, INCan is a national referral center, and its cases may reasonably reflect TGCT patients across Mexico (6). Compared to more complex methods such as GANs, synthpop remains a transparent and accessible approach that preserves essential statistical properties, enables a novel dataset expansion without discarding variables based on arbitrary thresholds, and facilitates the identification of potential prognostic markers that might otherwise be overlooked.
Although synthpop provides a valuable approach for increasing statistical power in small cohorts, its limitations should be acknowledged. The limited number of carriers in the original cohort may restrict detection of statistically significant associations, and synthetic data do not perfectly reflect a real population; rather, they model what would occur in a population with similar characteristics to the observed cases. Nonetheless, synthpop is an accessible, transparent, and easily applicable method that preserves essential statistical properties, allows dataset expansion without discarding variables based on p-value thresholds, and facilitates identification of potential biological risk factors. Additionally, the synthetic data benefit from the package’s built-in prospective design, which anonymizes patient information, improving ethical considerations and compliance.
Importantly, integrating synthetic data generation with machine learning validation represents a novel framework for augmenting small cohorts, including in TCa, and is generalizable to other rare conditions where limited sample sizes hinder robust statistical inference. Despite the strengthened findings provided by synthetic data, further research in slightly expanded multi-center cohorts is needed to confirm these results, explore additional genetic variants, and assess the robustness of this approach, ultimately supporting the prioritization of candidate biomarkers and clinical factors for translational applications.
{kind=link}
{kind=link}